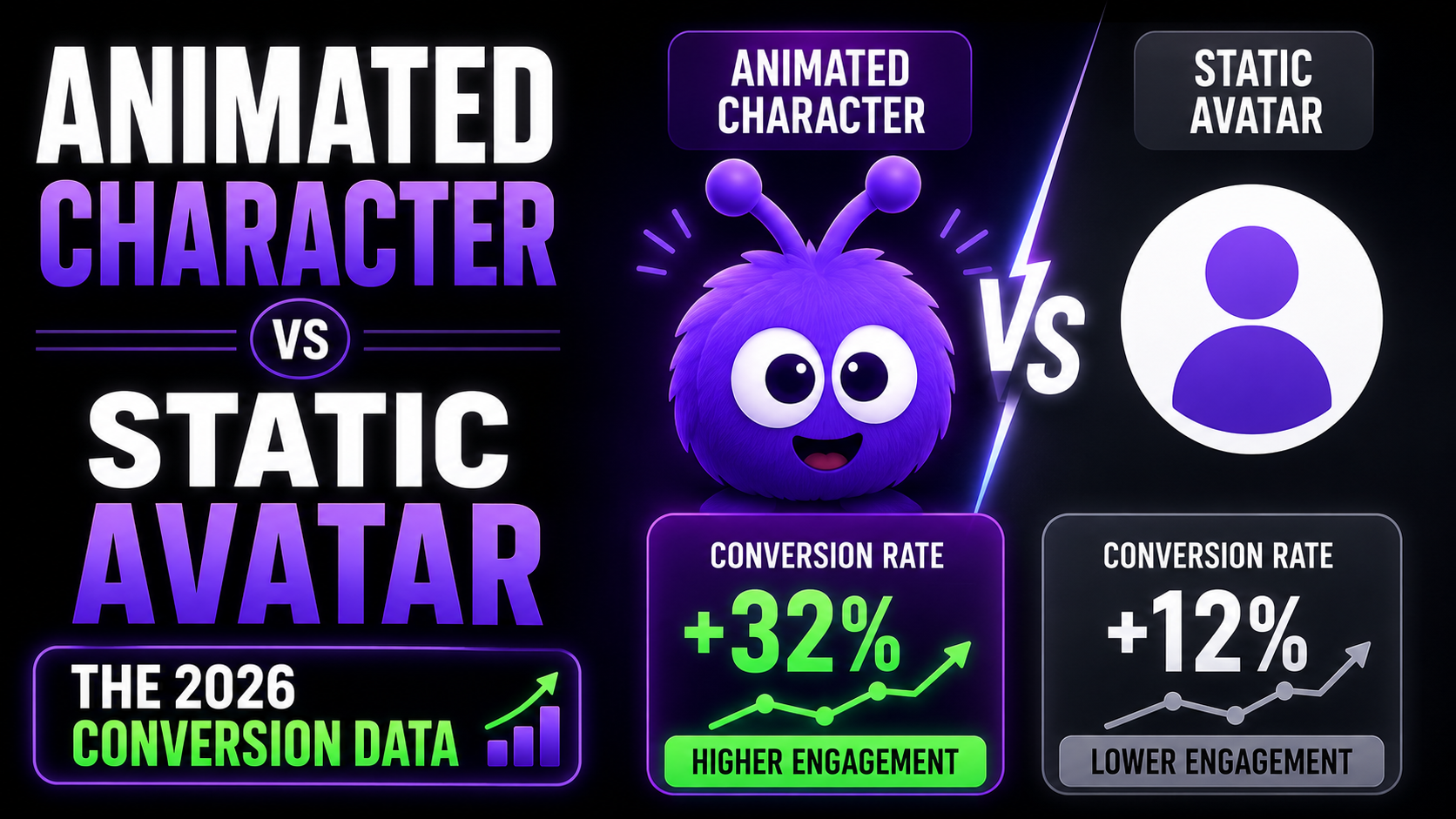
For most of the 2018-2024 chat-widget era, the avatar was a static circle: a stock photo of a support rep, or a flat illustration sitting in the corner. The mascot category swapped that circle for an animated character driven by a state machine. The question worth asking is whether the swap actually changes how people behave, or whether it is just nicer to look at.
The runtime work that makes the swap practical is covered in the Rive animation for ecommerce guide. This piece is about the conversion question.
What does the conversion data say?
The honest starting point: an animated, behavior-reactive character tends to beat a static avatar on both engagement (the share of visitors who actually interact with the agent) and on conversion once they do. Engagement and conversion move together here, though they are not the same thing, and a well-built animated character lifts both.
We are not going to put a single Yokaify lift number on it, because the size of the effect depends on your traffic, your offer, and how restrained the agent is. What is worth understanding is why the animated version pulls ahead, because the reasons also tell you how to build it badly. The cost side is real and asymmetric: animation spends bundle weight and CPU, and a static image effectively spends neither.
Why does animation produce more lift than a static avatar?
Three mechanisms, and they stack.
Attention, without interruption. Motion at the edge of your vision gets processed before you consciously look at it. A static avatar sitting in the corner is technically in peripheral vision but never surfaces; an animated character with an occasional small movement, a blink, a head turn, a small wave, does. Calibrated well, the visitor notices the motion without being yanked out of whatever they were reading. The eye-tracking research on peripheral motion is decades old; pointing it at a chat avatar is the newer part.
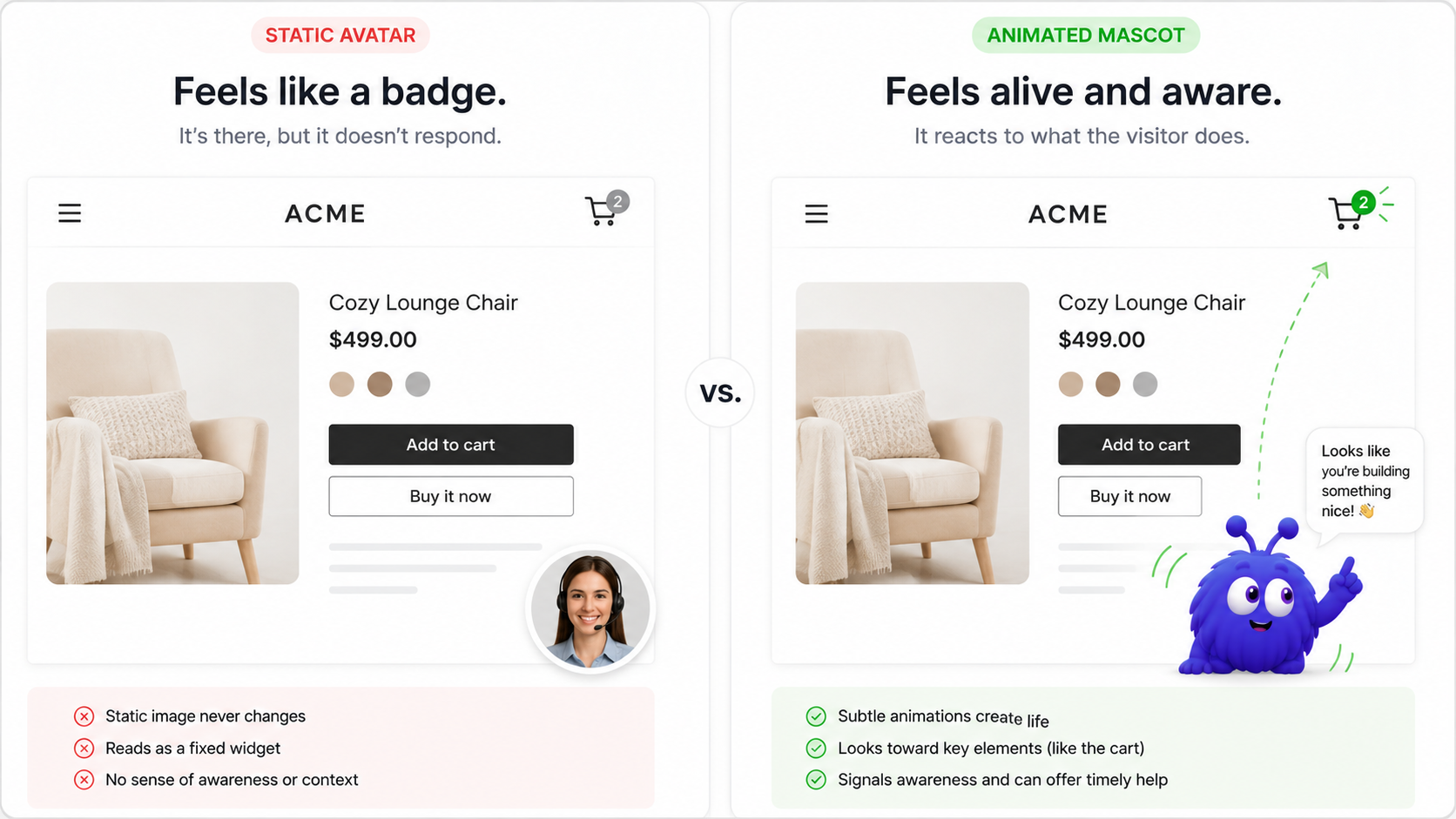
Reactivity through a state machine. This is the mechanism that does the most work. A mascot that moves from idle to attentive as the cart fills, from attentive to speaking when it has something to say, from speaking to celebrating on a purchase, reads as something that is aware of its surroundings. The same character looping one gesture regardless of context reads as wallpaper. Same art, two animation strategies, very different outcomes. The Rive animation tutorial goes deep on how that is wired.
Small expressions that add up. A static avatar has one face. An animated character has many small ones tied to what is happening: eyes that follow the cursor on hover, a blink during idle, a tilt when it turns its attention to you. Each is tiny. Together they make the character read as an agent rather than a logo with a personality sticker.
The three are independent. Take any one away and you lose part of the effect.
Does animation hurt Core Web Vitals?
It can, and the wrapper has to be built to stop it.
Load a full animation runtime plus a motion library on the marketing-page critical path and you are pushing a few hundred KB of JavaScript and animation work before the page is interactive. The fix is to keep the runtime out of the server bundle with a dynamic import (next/dynamic({ssr: false})), then mount it lazily with an IntersectionObserver so it does not load until the agent is near the viewport. The pattern is documented in the Next.js Rive wrapper.
CPU on cheap phones. A continuously running animation costs a few percent of CPU on a mid-range Android. Most of that is invisible, but it can show up in INP when the visitor interacts mid-animation.
LCP on slow networks. The mascot is rarely the LCP element, that is usually the hero image, but a carelessly wrapped runtime can fight the hero for bandwidth on a slow connection. Apply lazy-loading semantics to the mascot mount and set priority on the real LCP element.
None of this is optional. Ship an animated mascot without dynamic import, lazy mounting, and reduced-motion handling, and you will see Core Web Vitals regressions.
What about prefers-reduced-motion?
Required, not optional. Check the prefers-reduced-motion: reduce media query on mount, and if it is set, render the mascot as a static SVG of its idle frame. The point is that the fallback is a still illustration, not an empty box; the agent surface stays present and usable. Showing a reduced-motion visitor a static character is right. Showing them nothing — a blank corner where a character used to be — is just an unsettling little void, and nobody warms to a void.
The same wrapper should respect data-saver and slow-connection hints (the Save-Data header, the Network Information API), serving the static fallback regardless of motion preference. Treat that static frame as the agent's floor: the lowest-fidelity version everyone still gets.
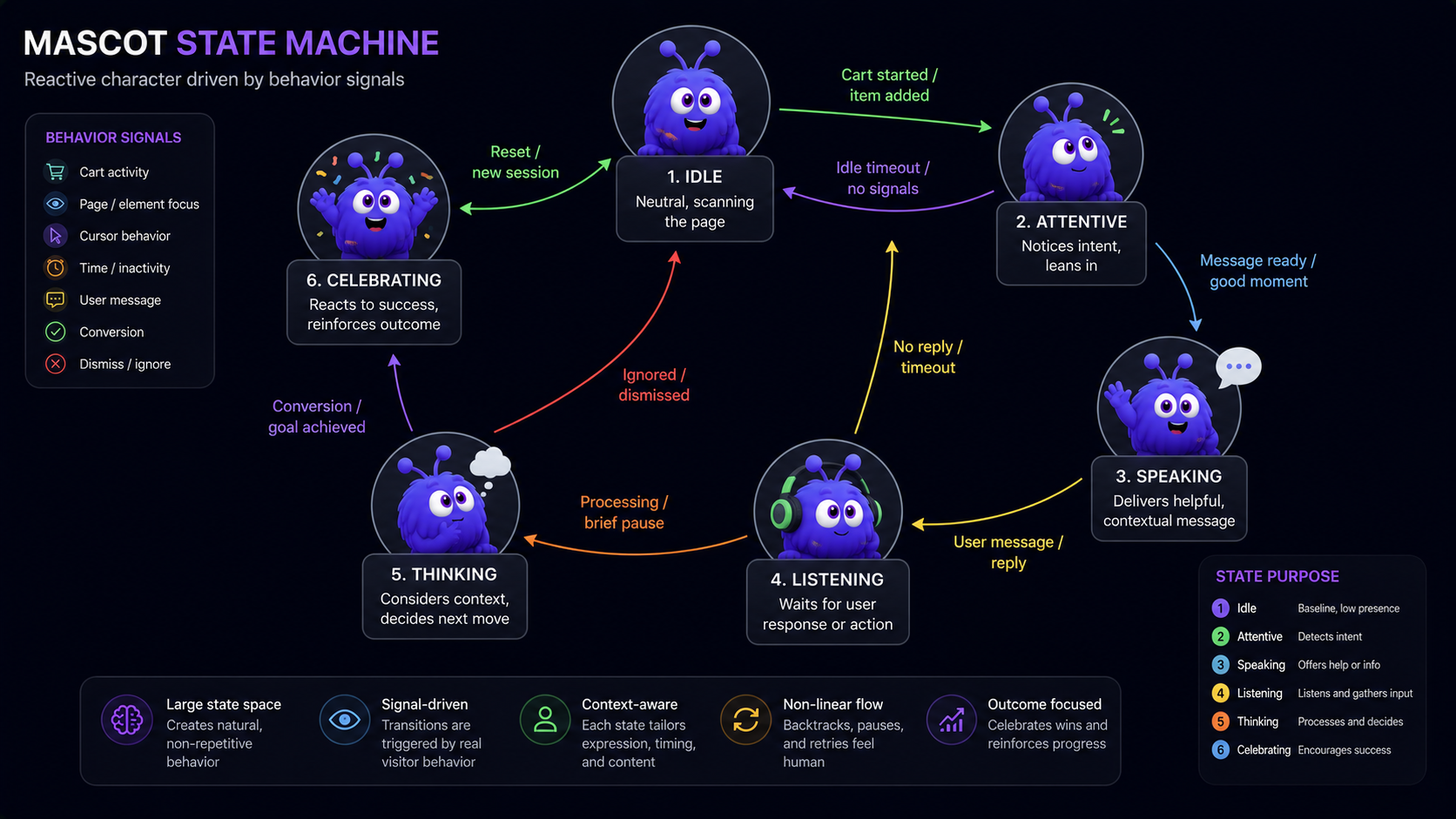
Why state-machine reactivity over keyframe animation?
The performance reason: state-machine animation runs inside the animation runtime, with React passing only state inputs across the boundary. Drive keyframes from React state instead and every animation frame re-renders the React tree, a re-render storm. With a state machine, React owns state, the runtime owns animation, and the boundary is one input update per behavior change.
The product reason: a state-machine mascot can hold a large set of states, idle, attentive, looking around, speaking, listening, thinking, waving, celebrating, surprised, and move between them on behavior signals without React knowing or caring. The character reads as agentic because its range is wide enough to express it.
The Rive animation tutorial covers the input types and the transition graph in detail.
What should buyers check before picking a mascot product?
A few questions cut straight to whether a vendor built this carefully:
- Is the animation reactive or just looping? Ask whether the character responds to behavior or plays the same idle regardless of context. Reactivity is where the lift comes from; a looping GIF in a fancier wrapper is not the same product.
- How does the runtime mount? The good answer names dynamic import, lazy mounting with an IntersectionObserver, pausing when the tab is hidden, and a reduced-motion fallback. The bad answer is "we just import it at the top of the file," which is how you ship a Core Web Vitals regression.
- What does a reduced-motion or slow-connection visitor see? A static character, not a blank corner. If the vendor cannot answer, the accessibility floor probably is not there.
The short version: animation is where the lift comes from, bundle weight and CPU are the price, and a state machine plus a careful wrapper is what makes the trade pay off.
Further reading
- GuideHow rive fits ecommerceThe runtime guide that covers the wrapper patterns referenced here.
- GuideAI mascot strategy guideThe 2026 implementation framework.
- BlogRive animation tutorial (2026)The deep dive on the state-machine reactivity mechanism.
- BlogRive vs Lottie: the honest 2026 comparisonWhy Yokaify chose Rive over Lottie for the animated mascot.
- ToolNext.js Rive wrapper generatorThe wrapper code referenced in the performance section.
Frequently asked questions
Attention capture (peripheral motion), state-machine reactivity (the mascot responds to behavior), and humanization (small expressions). Each contributes; reactivity is the largest single mechanism.
Last updated June 10, 2026.